
Protobuf Data Preprocessing
After the Protobuf data is collected from producers in the central bucket (under /protobuf subfolder), before being processed further by the ETL, the data will be preprocessed by a flow shown in the following diagram:
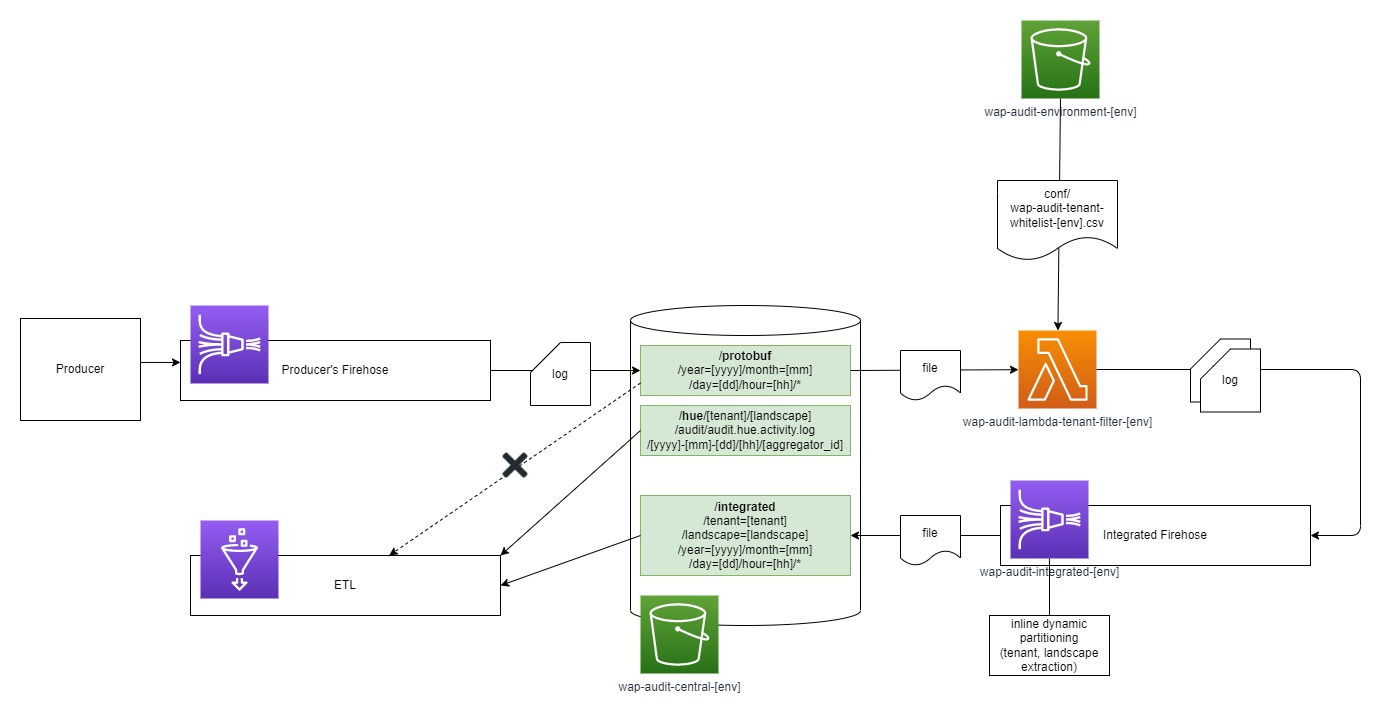
All Protobuf data from all producers in any tenant/landscape connected to a particular WorksAudit’s environment will be collected in the /protobuf subfolder in wap-audit-central-{env} central bucket (where env is the name of environment). This subfolder has the following structure:
year={yyyy}/month={MM}/day={dd}/hour={HH}/
The files in these folders typically have the following naming format:
{AWS-account-id}-{AWS-region}-{stream-name}-{datetime}-{generated-id}.gz
As can be seen from above structure, we cannot identify which data are coming from which tenant/landscape just by looking at the folder structure and the file name. In fact, different tenant/landscape from the same AWS account using the same Firehose will end up mixed in the same files. It is impossible to separate tenant and landscape at this file level.
New file being written to /protobuf folder will trigger a lambda called wap-audit-lambda-tenant-filter-{env}. The purpose of this trigger is to check if the tenant/landscape origin of the log is whitelisted in the whitelist file called wap-audit-tenant-whitelist-{env}.csv stored in the wap-audit-environment-{env} under /conf folder.
The whitelist file wap-audit-tenant-whitelist-{env}.csv contains a list of tenant and landscape like shown as follows:
ki4g,production
shimz,production
Logs that are not originated in one of the registered tenant and landscape will be dropped. The filtered out logs will then be forwarded to another Firehose called wap-audit-integrated-{env}.
The integrated Firehose is simply distributes the records received from the previous lambda to appropriate folder. This Firehose uses JQ in dynamic partitioning to obtain tenant and landscape values from the log and distribute the files in the following folder structure:
integrated/tenant={tenant}/landscape={landscape}/year={yyyy}/month={MM}/day={dd}/hour={HH}/
With this folder structure we can identify which log files containing data from which tenant/landscape.