
Extract-Transform-Load (ETL)
WorksAudit ETL is a process that transform raw log data from HUE, Collab, EBM, AC, Expense to a common Parquet format searchable by AWS Athena service. This ETL is running as a Spark job in AWS Glue service.
Following diagram summarizes the structure of the ETL:
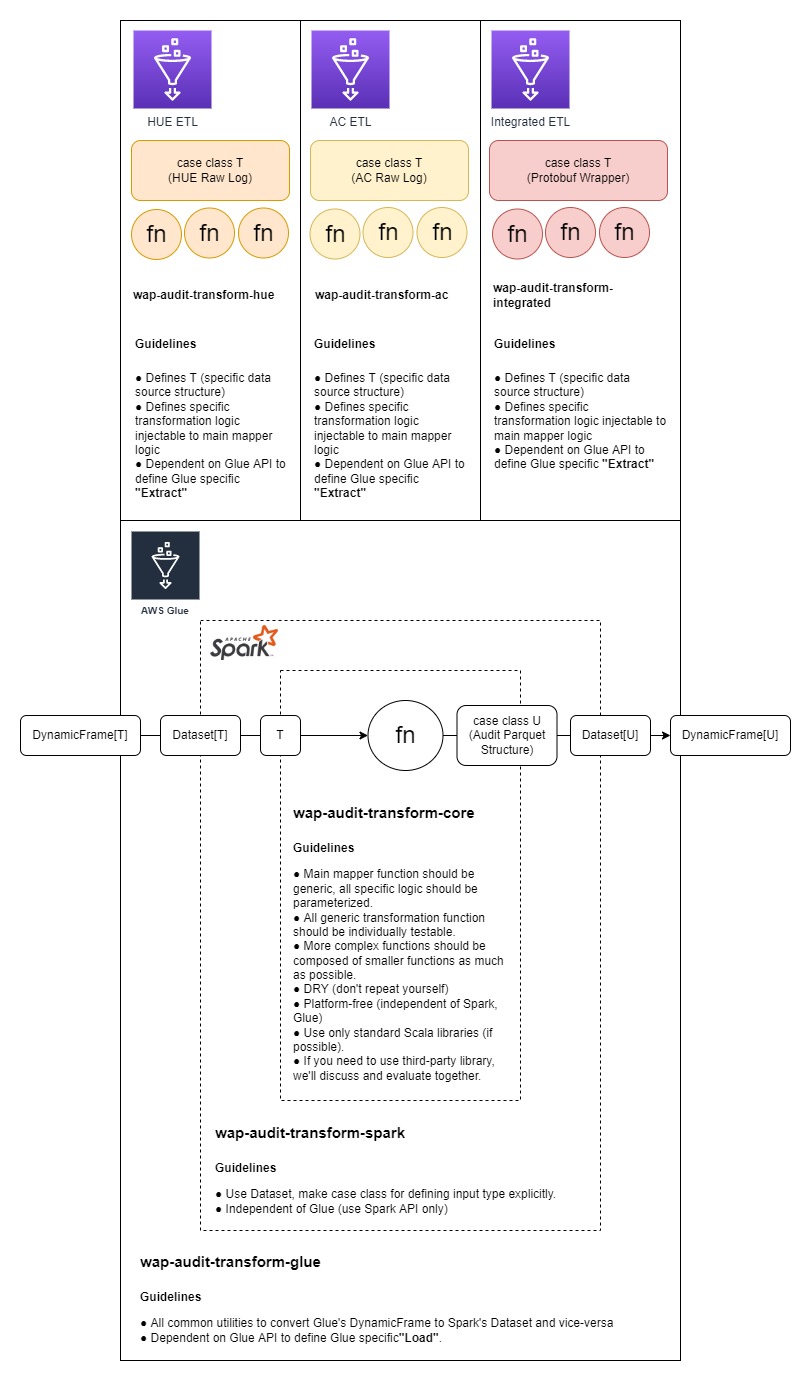
The diagram can be described as follows:
- All specific ETL logic (
integrated,HUE,AC) are based on (or an extension of) a collection of layered core modules (wap-audit-transform-core,wap-audit-transform-spark,wap-audit-transform-glue). - The vision is that in the ideal future, all logs are supposed to be in Protobuf format, thus only
integratedETL will be necessary. CurrentlyHUEand other ETL modules are necessary as a temporary solution to process existing log format. - The layered core modules are designed such that the inner layer is more “generic” or “platform-independent” than the outer layer:
- The innermost layer
wap-audit-transform-coreis the heart of the transformation that is simply a function that transforms one typeTto anotherU(Parquet data structure). - The next layer
wap-audit-transform-sparkhandles Spark-specific data type. It extracts the generic typeTfrom Spark data structureDataset. It also wraps the generic typeUin Spark data structureDataset. - The outermost layer
wap-audit-transform-gluehosts the Glue Job script that interfaces with AWS Glue system. This layer creates Spark data structure from Glue-specific data structureDynamicFrameand wraps the output back to this structure.
- The innermost layer
All the base ideas for the ETL are implemented in this module. Those are:
- Transformation. The transformation (
AuditTransform) is the heart of the ETL. It simply transforms input (AuditTransformInput) structure to the output (AuditTransformOutput) structure. - Sentence Generator. Sentence generator is a simple multilingual text processor that replaces variables in a string pattern with values. The main function for this pattern processing is here. As can be seen, the input of the function is the pattern, and all the components (subject, verb, object, etc.) that should replace the variables in the pattern specified.
- Multilingual Data Management. The multilingual data is accessible using an object called
MultilingualReferencewhich is basically an abstraction of a lookup engine.
This Core layer is independent of any execution environment, and dependent only on Scala standard libraries (and some additional general-purpose libraries, but not much).
The main logic of transformation is shown here:
def transform[T <: AuditTransformInput](input: T): AuditParquetOutput =
failableTransform(input) match {
case Success(value) => value
case Failure(exception) =>
// serialize the stack trace to string, and put it in an empty output's resources
// so that it can be logged by external process
val sw = new StringWriter
exception.printStackTrace(new PrintWriter(sw))
AuditParquetOutput.emptyOutput(sw.toString)
}
As can be recognized from the function signature, it simply transforms an input of type T (an extension of AuditTransformInput]) into an output of type AuditParquetOutput. How this is done is by doing a “failable transformation”. Failable transformation is defined as:
- Transformation of a set of data (fields) that some might fail individually, but the process of the whole transformation continues (resumes) to process another field. For example, the structure may include field
timeanduser. The transformation oftimedata may fail, but the process resumes to try to transformuser. - The transformation errors will be collected, and stored as part of the output.
- There may be some errors that are considered fatal. These errors will abort the whole ETL process.
failableTransform is a sequence of “extract operations” that the result is being set to the output. The actual value transformation itself are implemented in those extract operations. For example following is the first transformation:
val (tenantName, r1) =
resume(input.extractTenantName, AuditParquetOutput.emptyString, List())
The extractTenantName function, like all other extraction functions returns Try[T]. When an exception happen on extracting a value, tenantName will take a value of the default specified (AuditParquetOutput.emptyString), and the exception itself will not be thrown but appended to a List (third argument). r1 is the resulting List with possibly an exception appended. Note that the function is pure, and the output is a new List (not the same List being passed as argument).
The last extraction looks like this:
val (custom_meta_10, resumables) =
resume(input.extractCustomMeta10, AuditParquetOutput.emptyString, r74)
The output resumables is the final collection of exceptions that may happen during all extractions. This is then collected and put into transform_error: Array[String] field in the output:
resumables
.map(_.getMessage)
.toArray
The purpose of putting of the errors in the output is so that:
- The transformation can always be successful (not being stopped because some of bad data). Audit log is produced by many products and will inevitably contain some unclean data.
- The Viewer may decide on how to present the unavailability of a value to the end user.
The sentence generator and multilingual data management architecture is as follows:
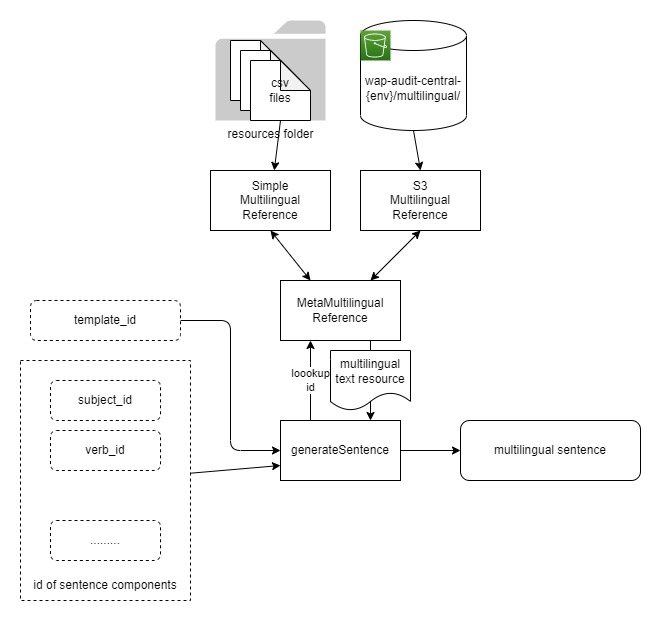
The generateSentence function receives IDs of multilingual resources (sentence pattern and sentence components IDs), and uses MetaMultilingualReference to resolve the actual multilingual value of all specified IDs.
Following code shows how this generateSentence code is being used:
for (tenant <- extractTenantName;
landscape <- extractLandscapeName;
sentenceId <- resolveSentenceId;
userId <- extractUserId;
verbId <- extractVerbId;
objectId <- extractObjectId;
indirectObjectId <- extractIndirectObjectId;
modifierId <- extractModifierId;
word1Id <- extractWord1Id;
word2Id <- extractWord2Id;
word3Id <- extractWord3Id;
word4Id <- extractWord4Id;
word5Id <- extractWord5Id)
yield
MultilingualSentenceUtil
.generateSentence(
ref = MetaMultilingualReference,
patternId = sentenceId,
subjectId = Some(userId),
verbId = Some(verbId),
objectId = Some(objectId),
indirectId = Some(indirectObjectId),
modifierId = Some(modifierId),
word1Id = Some(word1Id),
word2Id = Some(word2Id),
word3Id = Some(word3Id),
word4Id = Some(word4Id),
word5Id = Some(word5Id)
)(
subjectLookup = multilingualSubjectLookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
verbLookup = multilingualVerbLookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup
},
objectLookup = multilingualObjectLookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
indirectLookup = multilingualIndirectLookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
modifierLookup = multilingualModifierLookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
word1Lookup = multilingualWord1Lookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
word2Lookup = multilingualWord2Lookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
word3Lookup = multilingualWord3Lookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
word4Lookup = multilingualWord4Lookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
},
word5Lookup = multilingualWord5Lookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
}
)
.map(_.asMultilingualJson) match {
case Some(result) => result
case _ => throw new ResumableException("message.i18n.unresolvable")
}
The try-yield structure is basically instructing to “extract all necessary IDs”, if one of the ID is invalid, then the output sentence is invalid. Most of these extraction function will return a default value (ID for empty string mostly), even when it is unable to extract any ID.
Some ID lookup could be tenant-landscape specific, thus the lookup function used passes tenant and landscape arguments:
subjectLookup = multilingualSubjectLookup match {
case Some(f) => f
case _ => MetaMultilingualReference.lookup(tenant, landscape)
}
In above case subject is tenant-landscape specific (subject is usually user ID, and users are tenant/landscape-specific).
The MetaMultilingualReference is a wrapper to available implementations of MultilingualReference trait. This meta object simply dispatches the lookup requests to 3 implementations of MultilingualReference:
ResourcesMultilingualReference. This object loads all multilingual text resource files listed inresources/multilingual.registryfile (which is actually all.csvfiles underresources. There is a reason why the object doesn’t just load everything underresources).- S3SimpleMultilingualReference. This object loads multilingual file from S3 bucket.
- S3TenantMultilingualReference. This object lazily loads multilingual file from S3 bucket for a specific tenant/landscape. Only when there is a lookup to a particular tenant/landscape will the file loaded.
All multilingual string resources, whether stored in resources folder (baked into the ETL jar file), or stored remotely in S3 bucket has the same format, that is a “modified” CSV file. The parser for this CSV file is defined here. The rules are:
- Empty, whitespace-only lines will be ignored.
- Lines started with
#will be ignored. Usually these lines are used for comments. - Only 3 fields currently can be defined, separated by commas, in the following order:
id: identifier of the multilingual string resource.en: English version of the text.ja: Japanese version of the text.
- Comma within the text can be escaped using backslash. e.g.
I\, robot.
Following are some example of the entries:
# some examples
# this is the name of an activity, the ID will have following format:
# generic/activity/{activity-id}
generic/activity/web/open/page,Page Opening,画面の表示
# this is an example of sentence pattern
generic/active.svo,${subject} ${verb} ${object}.,${subject}が${object}を${verb}しました。
The purpose of the Spark layer is to make the Core layer executable in a Spark cluster. The main function for transformation using Spark is SparkAuditTransform.transform as shown here:
def transform[T <: AuditTransformInput](spark: SparkSession,
input: Dataset[T]): Dataset[AuditParquetOutput] = {
input
.map(AuditTransform.transform)(Encoders.product[AuditParquetOutput])
.filter(maybeEmpty =>
if (maybeEmpty.isEmpty) {
logger.error("Error transforming input: " + maybeEmpty.resources)
false
} else true)
}
The transformation from Spark perspective is basically just mapping all the contents of the Dataset using Core layer’s AuditTransform.transform. To see how this function executed in Spark, see the stand alone tester.
One of the most important task for Spark layer is to load data source into a data structure that implements AuditTransformInput trait.
ETL need to read from different kind of data sources (Protobuf, HUE raw log, etc.) and load it to different type of AuditTransformInput implementations, e.g. AuditIntegratedTransformInput for Protobuf, and AuditHueTransformInput for HUE. Following function SparkAuditTransform.transform:
def loadDataset[T <: Product](inputClassName: String,
dataFramePreprocessorName: Option[String],
dataFrame: DataFrame): Dataset[T] = {
val preprocessor: DataFrame => DataFrame =
preprocessFunction(inputClassName, dataFramePreprocessorName)
.getOrElse(dataFrame_ => dataFrame_)
preprocessor(dataFrame)
.as(
newProductEncoder(
typeTag(inputClassName)
)
)
}
The typeTag is a reflection utility to load the class given a class name. This class type would then be used to create an encoder to read the data source (in Spark’s DataFrame into the type specified in the argument). Note that some input class needs to be preprocessed, this can be customized by passing a function name into dataFramePreprocessorName argument. An example of this is following Glue argument for AuditIntegratedTransformInput:
--AUDIT_INPUT_DATAFRAME_PROCESSOR_FUNCTION=preprocess
This will load the function AuditIntegratedTransformInput.preprocess to preprocess the data before being processed in the transformation.
Glue layer is basically the one Glue job script that calls the Spark layer. This is the entry point of the whole ETL process.
Following are the steps in the script:
- Processing mandatory arguments.
val args = GlueArgParser.getResolvedOptions( sysArgs, Seq( "JOB_NAME", "AUDIT_INPUT_DB_NAME", //.... ).toArray ) Job.init(args("JOB_NAME"), glueContext, args.asJava) val inputDatabaseName = args("AUDIT_INPUT_DB_NAME") // .... - Processing optional arguments.
val preprocessorArgName = "AUDIT_INPUT_DATAFRAME_PROCESSOR_FUNCTION" val inputDataFramePreprocessorName = if (sysArgs.contains(s"--$preprocessorArgName")) Some( GlueArgParser.getResolvedOptions(sysArgs, Array(preprocessorArgName))( preprocessorArgName)) else None // .... - Getting the data source. Depending on whether filter expression (to limit the processing, i.e. for only certain dates) is provided, pushDownPredicate is being used.
val dataSource = partitionFilterExpression match { case Some(expression) => glueContext .getCatalogSource( database = inputDatabaseName, tableName = inputTableName, redshiftTmpDir = "", transformationContext = "auditDataSource", pushDownPredicate = expression ) .getDynamicFrame() case None => glueContext .getCatalogSource( database = inputDatabaseName, tableName = inputTableName, redshiftTmpDir = "", transformationContext = "auditDataSource" ) .getDynamicFrame() } - Calculating data repartition. This repartition is used for data processing optimization. Due to different nature of the data source (some have large number of small size partitions, some have small number of large size partitions), adjustments to the number of partitions can be made by pasing different values. No definite rules on the right value for repartition arguments, it’s mostly set based on experiments.
val repartitionNum = { if (partitionTarget > 0) partitionTarget else if (repartitionMultiplier >= 0) repartitionMultiplier * dataSource.getNumPartitions else dataSource.getNumPartitions / repartitionMultiplier.abs } - The data transformation using Spark layer.
val outputDataset = SparkAuditTransform.transform( glueContext.getSparkSession, SparkAuditTransform.loadDataset( inputClassName, inputDataFramePreprocessorName, if (repartitionNum > dataSource.getNumPartitions) dataSource .repartition(repartitionNum) .toDF() else if (repartitionNum < dataSource.getNumPartitions && dataSource.getNumPartitions >= coalesceThreshold) dataSource .coalesce(repartitionNum) .toDF() else dataSource.toDF() ) ) - Writing the output.
val outputDynamicFrame = DynamicFrame.apply(outputDataset.toDF(), glueContext) glueContext .getSinkWithFormat(connectionType = "s3", options = JsonOptions( Map("path" -> outputPath, "partitionKeys" -> Array("tenant_name", "landscape_name", "date"))), format = "parquet") .writeDynamicFrame(outputDynamicFrame)
Integrated ETL is the implementation of data transformation for Protobuf data source. The main class is the implementation of AuditTransformInput trait, that is AuditIntegratedTransformInput. The signature of the class constructor is as follows:
case class AuditIntegratedTransformInput(tenant: String = "",
landscape: String = "",
service: String = "",
timestamp: Long = 0L,
data: String = "",
version: AuditProtobufProducerVersion =
AuditProtobufProducerVersion())
extends AbstractAuditTransformInput {
//.....
}
This constructor will be automatically called by the Spark layer when reading the JSON from the data source. Following is a sample record of the data source that will populate the argument values:
{"tenant":"ki4g","landscape":"production","service":"wap/hue","timestamp":1628725129,"version":{"platform":"java","protobuf":"1.0.15","producer":"1.10.0-SNAPSHOT"},"data":"Ci....=="}
data field is the encrypted Protobuf data that contains the actual audit log. The data itself then will be processed by Protobuf deserializer:
val activity = new ProtobufActivity(data)
The rest of the code is basically extracting information from Protobuf data.
Many of activities have different way to extract values. To represent this difference an abstraction called logic is used. An example on where this logic is used is here:
override def extractActivityType: Try[String] =
activity.clause
.flatMap(_.logic)
.flatMap(_.activityType)
This code shows that the activity-specific logic is loaded in order to get activityType.
There are many implementations of logic in com.worksap.company.audit.transform.integrated.protobuf.logic package. Many activity types share logic implementations, some have their own specific implementation. Most of logic are direct or indirect descendant of DefaultLogic.
How the correct logic is being loaded is implemented in ProtobufActivityClause:
private val webPattern = raw"/web/(.*)".r
// ...
def logic: Try[ActivityTypeLogic] = activityType.map {
case webPattern(restOfType) =>
if (restOfType == "open/page") {
if (this.activity.description.startsWith("collabo/authn")) {
new DefaultLogic(
this,
verbIdCustomizer = _ => Some("generic/verb/access"),
modifierIdCustomizer = _ =>
new ProtobufMapHelper(activity.context)
.get(HueContextKey.CLIENT_IP_ADDRESS.name),
objectIdCustomizer = _ => Some("special/word/the.login.page")
)
// .....
}
// ....
}
//.....
}
In this structure activityType is being mapped to DefaultLogic when it matches the webPattern regular expression (started with /web/), and followed by string open/page, etc.
HUE module is the ETL for transforming HUE Native Raw Log format. The main implementation is AuditHueTransformInput. HUE Raw Log file is a collection of tab-separated values with an encrypted payload containing the actual audit log. This tab-separated values will be automatically passed into the raw_log argument:
case class AuditHueTransformInput(raw_log: String,
tenant: String,
landscape: String,
log_type: String,
audit_log_type: String,
date: String,
log_section: String,
aggregator_id: String) extends AbstractAuditTransformInput {
val hueRawLog: HueRawLog = new HueRawLog(raw_log)
// ....
}
HueRawLog class decrypts the payload and deserialize the fields.
Like in Integrated ETL, HUE also has different logic to handle different activities. The logic is instantiated here like:
val logic: Try[HueActivityTypeLogic] =
hueRawLog
.triedPayload
.flatMap(_.activity)
.flatMap(_.logic(hueRawLog) match {
case Some(value) => Success(value)
case _ => Failure(new IllegalArgumentException("Unable to resolve logic"))
})
Loading appropriate logic for an activity type is performed here, like:
val MAPPING: Map[String, HueActivityMetadata] = Map(
// -------------------------------------------------------------------------
// Data activity
// -------------------------------------------------------------------------
"DATA_CHANGE" -> HueActivityMetadata(
"/data/operate/data",
l => new DataChangeLogic(l)
),
// .....
For each of the HUE’s native activity type (e.g. DATA_CHANGE), there is an equivalent WorksAudit activity type (e.g. /data/operate/data) and associated logic to handle data extraction (DataChangeLogic in above example).
AC module is for transforming AC “access log”. The main implementation class is `ACTransformInput:
case class AuditACTransformInput(csv: String,
tenant: String,
landscape: String,
year: String,
month: String,
day: String)
extends AbstractAuditTransformInput {
// ....
}
AC access log format is basic CSV and that value will be injected to csv argument of this class.
The other important class for this ETL module is the mapping from AC’s activity type to WorksAudit activity type:
case class ACActivityMapper(csvRecord: ACCSVRecord) {
def activityType = csvRecord.messageCode match {
case Some("1009000002") => Success("/authentication/login/nil/success")
case Some("1009000003") => Success("/authentication/logout")
//....
Note that this file is autogenerated by using /scripts/generate_ac_activity_mapper.py script. In order to update the mapper file, update the specification file before running the sript.